ESPN fantasy football projection are free and available historically. Although they differ from DraftKing, they are granular enough to be converted and compared. Let’s see their predictive power
In this post we’ll use ESPN predictions to optimize our fantasy pool. You can skip to the bottom for the code or just visit my github. For more information on R programming for data science, I recommend the book Practical Statistics for Data Scientists
This post is a continuation of my series on using data science to make fantasy football picks. For more information, see my last two posts:
- Using Python and Linear Programming to Optimize Fantasy Football Picks
- Using Linear Regression to Make Fantasy Football Picks
Why You Shouldn’t Pay for Predictions
The adage “those who can’t do, teach” is a bit harsh on teachers. However, in the prediction market it makes much more sense. If you had a statistical edge into a deep liquid market such as fantasy sports, you’d be wise to exploit the edge yourself rather than sell it. You can try to do both, make your picks and then scream them from the rooftop. In fact, that’s often what hedge fund managers do since they know convincing enough investors will make their prediction a self fulfilling prophecy as new money comes in and moves prices.
But with fantasy sports you’re stuck in your position, so there is no opportunity to sell your positions after salaries moved in your direction. So giving away your estimates can’t help you. But what can happen is that, if your model has value, others can gleam insights from your model, adjust their model and the salaries will move to reflect your edge. So over time you’ll lose your edge since it will be incorporated into the new salaries.

For that reason I cannot imagine anybody selling fantasy football is adding much value. A better technique would be to sell a number of different sub-optimal models. As some perform better or worse, you can drop the losers and promote the record of the sellers. Over time you’ll want to replenish your supply to keep this shell game afloat. Hedge funds do this as well.
ESPN Predictions
Everything I said above holds for free predictions as well, but there are other reasons someone may give out free predictions. The first one is obviously ads, but a company like ESPN may give out predictions in order to promote their own fantasy line. ESPN point system is slightly different from that of DraftKings, but ESPN predictions break down their predictions by attributes which allows us to convert between the two (e.g. rushing 16.5 yards). ESPN also generously provides us with historical predictions, which is very rare since that would allow people to easily track performance. However, they don’t provide historical weekly predictions from prior years, just the aggregate predictions from last year and the weekly predictions from this year.
So let’s see how ESPN did. We’ll start with updating the latest DK point history. I wrote about this function in my last post on using linear regression to make fantasy picks.
source("espn.R")
source("utils.R")
source("history.R")
source("available.R")
source("solve.R")
HISTORIC ANALYSIS OF ESPN SCORES
h <- getLatestHistory()
h <- updateHistory(h,save=T)
h <- enrichHistory(h)
h <- h[h$year == 2018,]
We then need to download the ESPN historic predictions and convert the score to DK points score. The function enrichEspn applies a soft-match on the name so for instance Allen Robinson II matches Allen Robinson.
# Review historic ESPN scores
espn <- getEspnHistory(2018, startPeriod = 1, endPeriod = 9, minPoints = 0)
espn <- enrichEspn(espn, h$displayName)
Finally, we can merge the two tables, limit to only those that have both an ESPN DK score and an actual score and see the correlation.
h <- merge(h, espn[c("displayName", "year", "week", "espn.dk.points")], by=c("displayName", "year", "week"), all.x=T)
espnCor <- h[!is.na(h$espn.dk.points),]
cor(espnCor$dk.points, espnCor$espn.dk.points)
# 0.65716
65% correlation between estimated and DK score is not bad, although it is biased with the players that ESPN predict score 0 and do in fact score 0. We can exclude those that have a predicted score below some threshold.
Let’s see how it would have do versus the actual scores:
lapply(seq(1,9), function(x) testWeek(espnCor, x))
[[1]]
[1] "predicted: 126.27 actual: 190.68 diff 64.41"
[[2]]
[1] "predicted: 128.516 actual: 151.88 diff 23.364"
[[3]]
[1] "predicted: 131.222 actual: 82.72 diff -48.502"
[[4]]
[1] "predicted: 137.284 actual: 164.6 diff 27.316"
[[5]]
[1] "predicted: 133.71 actual: 123.62 diff -10.09"
[[6]]
[1] "predicted: 134.902 actual: 136.5 diff 1.598"
[[7]]
[1] "predicted: 136.448 actual: 153.96 diff 17.512"
[[8]]
[1] "predicted: 141.766 actual: 176.96 diff 35.194"
[[9]]
[1] "predicted: 143.468 actual: 123.46 diff -20.008"
Our actual score is usually higher than our predicted which means ESPN is pretty conservative, although week 3 is way off. How good the model is depends on your competition so I would recommend comparing these actual scores to your particular contest.
Drafting a DK Fantasy Team Based on ESPN Predictions
To use the converted ESPN scores to select a fantasy team, we can just do the following:
# CHOOSE FROM AVIALABLE BASED ON ESPN SCORES
WEEKS_ID <- 22434
WEEK <- 9
YEAR <- 2018
a <- getLatestAvailable(WEEKS_ID)
ah <- availableToHistory(a, week = WEEK, year = YEAR, displayNames = h$displayName)
ah <- merge(ah, espn[c("displayName", "espn.dk.points")], by = "displayName")
ah$prediction <- ah$espn.dk.points
ah <- merge(ah, unique(h[c("displayName", "median")]), by="displayName", all.x = T)
# Filter out those that don't have a prediction
ahFiltered <- ah[!is.na(ah$prediction),]
ahFiltered$pos <- as.factor(ahFiltered$pos)
solve(ahFiltered)
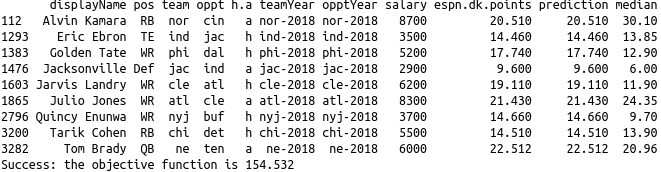
Optimal selection based on ESPN points
WEEKS_ID is a an identifier for your particular match-up. Go to your contest and see the link for Export to CSV.
Final Thoughts
Building a model for something as unpredictable as fantasy football is challenging. A popular strategy in prediction models is the ensemble method, that combines many imperfect models and weights them accordingly. It’s kind of how a choir of imperfect voices can sound good as different imperfections balance each other out. I take the same approach to outside predictions. No one is going to sell you the goose that lays the golden eggs, but with enough polish you can turn a turd into something useful.
By Branko Blagojevic on November 6, 2018.