Botrank tracks votes for reddit bots. Updating records can be surprisingly tricky. Lambda Architecture can help.
Lambda Architecture is a novel way to manage a database. Data is immutable and everything is built from the ground up. Everything can be re-created and nothing is lost.
In my last post I wrote about a few Reddit bots I am working on. One of them, B0tRank, keeps track of “good bot” and “bad bot” comments and updates a ledger that has a rating of bots based on these votes. The data is then uploaded periodically to a static site which display rankings.
I didn’t invent this concept. The original good-bot-bad-bot aggregator was /u/goodbot_badbot, but he had gone offline about a month ago and his site went down as well. I found an archived version of his site, downloaded the rankings and continued aggregating and displaying bot rankings.
At first I converted the rankings to a csv and wrote a bot that parses the comment and increments the respective good-bot or bad-bot score. But I started to have issues. I ensured that the csv was always grouped (i.e. no duplicate names), but for some reason it was always getting out of sync. I also had other bugs and over time I didn’t trust the csv.

Luckily I always kept all the logs of my bots actions. Here is an example of a single line of the log file:
2018-08-13 07:33:57,543 - B0tRank - INFO - postId: 96u8fk post: 101 in my opinion commentId: e43vwjm comment: good bot action: ___alexa___
When my csv became corrupted, I just wrote a simple script that would take the original starting csv I had from the original bot, read through all the logs, parse the action (good or bad) and user name and recreate the csv from scratch. It wasn’t very fast but it was reliable and consistent.
Eventually, I realized the backup of scraping the logs is better than the csv incremental method. The csv incremental method doesn’t keep track of individual votes but is supposed to be simpler to administer. And since it was failing on simplicity, I decided to rethink how I’m tracking everything.
This article was first published as exclusive content in partnership with Morning Cup of Coding. It’s a daily curated newsletter featuring technical articles on all fields of software engineering.
Lambda Architecture
Lambda Architecture (LA) is a generic, scalable and fault-tolerant data processing architecture. It’s used in organizations such as Walmart that require low latency and process a lot of data. The main benefit of LA is that the data is immutable so everything is a f(data), f(f(data)) and so on.
Immutable data means that no matter what happens I can rebuild and theoretically, recreate any prior view.
Adding more data to collect is also simpler and all the processing lends itself well to distributed systems like Hadoop Distributed File System (HDFS). Debugging is also easier since you can debug components independently. The criticism is that maintaining code that needs to produce the same exact result in two complex distributed systems is difficult (one for real-time and another for batch updates).
Big Data by Manning Publications uses an example throughout the book that is essentially my use-case. Instead of tracking votes, their example tracks clicks on websites. The book then goes on to describe a Lambda Architecture. The architecture is based on three layers: batch layer, servicing layer and speed layer. The data remains untouched and the batch and speed layers act of the data and the servicing layer acts on the batch layer. Queries on the data are based on the servicing layer and speed layer.
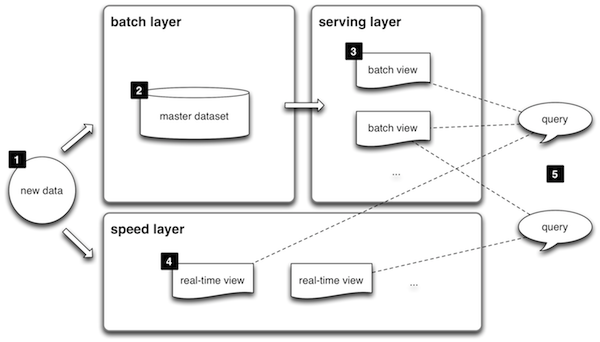
Lambda architecture
The book does a much better job explaining the concepts and the first chapter is freely available, so check that out if you want more information.
In my case, the data was my logs. The batch layer aggregates all the data and counts up the good and bad votes. The speed layer is used to update the records based on events that had happened since the last batch. It’s a lot faster since it only considers records after the last batch. And the serving layer is just the view. In my case, the servicing layer outputs a csv I can use to update my static site.
The best part is that at any given time, I can ditch everything, and recreate the batch from scratch. Also, if some data becomes corrupted (e.g. erroneous logs), I can just quarantine the logs and recreate all my batches.
I decided to write a Lambda Architecture from scratch and use the file system as my database.
Lambda Architecture from Scratch
Note that this is not necessarily efficient and I would not recommend rolling your own database from scratch. This is just for illustrative purposes.
I wanted my final file system to look like this:
logs
botrank
[user]
good
summary
[year]
[month]
[day]
[yyyy-mm-dd-hh:mm:ss]
[count up to that point]
[year]
[month]
[date]
[yyyy-mm-dd hh:mm:ss]
[count]
bad
...
The records are empty files with an integer as the file name. The batch process would take a given user and key, and sum up all the file-names, and update the summary directory.
Note that the final files are indexed by yyyy-mm-dd hh:mm:ss. So if two records come in at exactly the same second for the same bot and rating, only one will be represented. I could have made it down to millisecond or less, but its not necessary for my tracking as I don’t collect that many votes and votes for a given bot are not that common that a collision is highly unlikely. I could also choose to increment the count for duplicate layers, but that would mean if I migrated from my logs twice in a row, I would essentially double everyone’s score. This way I can always be sure that no record is double counted.
The first function I wanted is the ability to write a log. That means I have to get to the appropriate directory, creating the sub-directories as necessary and write a file with the name of its value.
def add_record(path: str, user: str, key: str, time: dt, val: int = 1):
""" Adds record for user and key sharded on time """
date_path = time_to_date_path(time)
time_path = time_to_time_dir(time)
final_dir = os.path.join(path, user, key, date_path, time_path)
if not os.path.exists(final_dir):
os.makedirs(final_dir)
final_path = os.path.join(final_dir, "{}".format(val))
with open(final_path, "w") as f:
f.write("")
return final_path
The function above relies on two helper functions: time_to_date_path and time_to_time_dir. These two functions take a datetime object and return a path and directory for our record, respectively.
TIME_FORMAT = "%Y-%m-%d %H:%M:%S"
DATE_FORMAT = "%Y/%m/%d"
def time_to_date_path(time: dt):
""" Converts datetime to folder path based on PATH_FORMAT """
return time.strftime(DATE_FORMAT)
def time_to_time_dir(time: dt):
""" Converts datetime to file name based on FILE_FORMAT """
return time.strftime(TIME_FORMAT)
Now we can do the following:
# Adding a base record
add_record(BASE_DIR, USER, "good", dt.min, val=100)
# '.../botrank/___alexa___/good/1/01/01/1-01-01 00:00:00/100'
add_record(BASE_DIR, USER, "good", dt.now())
# '.../botrank/___alexa___/good/2018/09/08/2018-09-08 07:53:47/1'
This first function call created a base record of 100. The second created a single record of 1. If we were to run the first function again, it would just override the original file since the time is that same.
The next step is to batch. The base-line batching takes place on a user and key level. It find all records for given user and key, sums up the file-names and adds a summary:
def batch(path: str, user: str, key: str):
""" Batches record for given path, user and key """
records_to_batch = get_records_filtered(path, user, key, dt.min,
RecordFilter.AFTER_OF_EQUAL)
return add_summary(path, user, key, dt.now(), records_to_batch)
In order to batch, we need a few more helper functions. First, we need to find the records to batch. For that I created a function get_records_filtered that finds all records given a user and key, and adds a summary. The get_records_filtered can be leveraged to perform the speed layer, where we only want to get records after a given period.
The get_records_filtered function is the most complicated function we’ll be dealing with since it involves parsing our file system and has flexibility to include only records before, before or equal, after or after or equal to a given datetime.
This is similar to glob where it walks through the file structure and returns only matching directories. I originally tried to use glob, but it doesn’t support full regex and I wanted to treat folders like integers rather than strings anyway.
For instance, if I’m looking for records after 2018/9/3, I only want to go through the year sub directories of 2018+. Then for months, I want to consider anything from year 2019+ and anything from 2018/9+, and so on.
The add_summary function is simpler, and just creates a batch key and adds a log to that batch_key.
BATCH_KEY = "summary"
def get_batch_key(key: str):
""" Converts a key into a batch key """
return os.path.join(key, BATCH_KEY)
def add_summary(path: str, user: str, key: str, time: dt, val: int):
""" Adds a summary record for user and key sharded on time """
new_key = get_batch_key(key)
val = "{}".format(val)
return add_record(path, user, new_key, time, val)
Now when I batch on a given key, I’ll create a summary record
# Batching all records
batch(BASE_DIR, USER, "good")
# '.../botrank/___alexa___/good/summary/2018/09/08/2018-09-08 07:54:51/101'
The summary value is 101 since we have two records, one with a value of 100 and another with a value of 1.
Now that we have a batch record, we need to be able to get the latest batch. But before we can get the latest batch record, we need a general function to return the latest record given a user and key. With that function, we can just create a batch_key and ask for the latest record for a user and batch_key. It would also be nice to have the option to return the value of the record or the actual record itself.
def get_latest_record(path: str, user: str, key: str, val: bool = False):
""" Returns latest record """
cur_path = os.path.join(path, user, key)
cur_sub_dirs = get_int_dirs(cur_path)
while len(cur_sub_dirs) > 0:
new_dir = max(cur_sub_dirs, key=lambda x: int(x))
cur_path = os.path.join(cur_path, new_dir)
cur_sub_dirs = get_int_dirs(cur_path)
latest_file = get_latest_in_path(cur_path)
if latest_file:
latest_path = os.path.join(cur_path, latest_file)
if val:
latest_file_val = sum([int(f) for f in os.listdir(latest_path) if f.isdigit()])
return latest_file_val
return latest_path
Here is get_latest_record in action:
get_latest_record(BASE_DIR, USER, "good", val=False)
# '.../botrank/___alexa___/good/2018/09/08/2018-09-08 07:53:47'
get_latest_record(BASE_DIR, USER, "good", val=True)
'1'
The latest record is the latest record we created given the user and key. And latest record value is just a sum of the file names in the record.
Now get_latest_batch is simply creating a batch_key and getting the latest record.
def get_latest_batch(path: str, user: str, key: str, val: bool = False):
""" Returns latest batch result """
new_key = get_batch_key(key)
return get_latest_record(path, user, new_key, val)
def get_latest_batch_time(path: str, user: str, key: str):
""" Returns time of last batch """
latest_batch = get_latest_batch(path, user, key, val=False)
return file_to_time(latest_batch)
Here it is in action:
get_latest_record(BASE_DIR, USER, "good", val=False)
# '.../botrank/___alexa___/good/summary/2018/09/08/2018-09-08 07:54:51'
get_latest_record(BASE_DIR, USER, "good", val=True)
'101'
The result is the latest batch.
We can batch as often as we would like and we have snapshots of prior batches saved. If the data becomes corrupted, we can delete or quarantine erroneous data and re-batch everything. Batching always happens from scratch.
But we may not want to batch from scratch. We may want to just reference the latest batch and batch all the records that came after the latest batch. We may want to reserve batching from scratch as a less frequent process or only to be triggered if historical data changes. That’s where the speed layer comes into play. The speed layer retrieves the time of the latest batch, searches for records after that batch, counts the values and creates a new batch based on the prior batch and any records that came in after the prior batch.
def update_batch(path: str, user: str, key: str):
""" Updates summary without going through all records"""
latest_batch_val = get_latest_batch(path, user, key, val=True)
latest_batch_time = get_latest_batch_time(path, user, key)
records_to_update = get_records_filtered(path, user, key,
latest_batch_time, RecordFilter.AFTER_OF_EQUAL)
update_val = int(latest_batch_val) + records_to_update
return add_summary(path, user, key, dt.now(), update_val)
And that’s the basics of my Lambda Architecture. There are a few other functions I added like batching on a given user for all keys or batching on all users, but that just amounts to iterating through all users/keys and running the respective underlying functions.
The core tenet of Lambda Architecture is that the data is immutable. Everything else is a direct result from that fact.
Views have to be built from the data, which may require other views. Views are essentially cached and updated through speed layers.
In my use-case, I’m tracking good/bad votes for bots. Every time a vote comes in I have a function update_bot:
def update_bot(bot, bots_path, good, save=False):
key = "good" if good else "bad"
return add_record(DB_PATH, bot.lower(), key, dt.now(), val=1)
When it comes time to update the site, I re-batch all the records with a speed layer.
def update_and_write(db_path: str, log_path: str, csv_path: str):
_ = update_all_users(db_path)
write_to_csv(db_path, log_path, csv_path)
Periodically I run a full batch to ensure a correct starting state for my regular updates.
_ = batch_all_users(db_path)
For full implementation and examples, check out the github repo.
Further reading:
- Big Data
- Lambda Architecture
- How we built a data pipeline with Lambda Architecture using Spark/Spark Streaming
- Questioning the Lambda Architecture
By Branko Blagojevic on September 9, 2018