Evolutionary learning models are a great introduction to machine learning because they’re simple to understand conceptually and…
Evolutionary learning models are a great introduction to machine learning because they’re simple to understand conceptually and surprisingly easy to implement. In this post, I’ll create an evolutionary learning model to use on the OpenAI. The great thing about OpenAI is the simple API and large number of environments to experiment on. So any bot we create in one environment can (in theory) be used on any other environment. It might not work well, but if setup correctly, it could work across most if not all environments.
All the code below is available here under Part 1.5 — Evolutionary Models. Or check out part 1 of my series on reinforcement learning.
Before I get into evolutionary learning, let’s talk a little about what a game state represents. The games we’ll be looking satisfy a Markov property, which basically means that everything that comes after a state is dependent only on that state. So for instance, rolling a die is Markovian since prior rolls have no bearing on future rolls. However, drawing red/black balls from an urn without replacing them is not Markovian since after each draw the proportion of red to black balls changes. More examples can be found here.
So a state is just a representation of a game. It can be units, pixels, text, pretty much anything that tells you what’s going on. We’ll first be using Cartpole, which is a game in which you try to balance a pole on a block. You can move the block right or left but if the stick falls over, you lose.
The state is represented by 4 values:

What the values represent is unimportant to our algorithm. All we need to know is that there are 4 variables and 2 actions.
We want a way to interact with the state (a list of length 4) and decide which action to take (2 possible actions). One way we can easily do this is to create a 4 x 2 matrix and use the dot product with the state and take the highest value.
Below is an example of how it works. The state is on our left, the weight matrix is in the middle and the output is on the right. We don’t care much what the output is, we just take the higher number of the two to decide which action to take (2 possible choices).
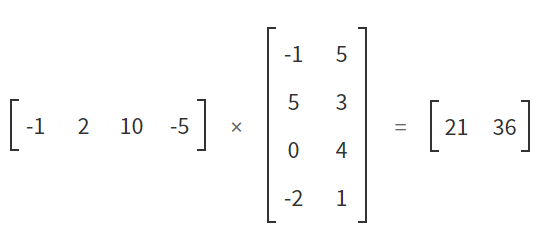
http://matrixmultiplication.xyz/
So our bot for this game will be a matrix of 4 x 2, or generally, our bot will be a matrix of shape state_shape x num_actions.
On to evolutionary learning.
Evolutionary learning has three main pillars that drive learning:
- Survival of the fittest
- Mutation
- Breeding
Survival is the likelihood that our bot will survive. For that we need a function to determine how fit a bot is. The simplest way to do this is to just run a bunch of simulations and take the average score. You can get fancy later and have different scoring functions like consistency or reduce probability of terrible score, but this is good enough. Use the score to figure out which bots to kill off.
Mutations take the population, mutate it by randomly changing some characteristics and introducing them into the population. In our case, our bot is just a 4 x 2 matrix, we can just randomly add some Gaussian noise.
Breeding takes individuals from a population and breeds them by taking some values from one parent and other values from another. So in our bots, we have a 4 x 2 matrix, so we just take some values from one parent and the rest from the other parent. The idea is that if the features are encapsulated well enough, then taking some trait from two relatively fit parents could result in a more fit offspring. For instance, if mom is good at basketball because she’s fast and dad is good because he’s tall, chances are high their offspring may be both tall and fast, making him great at basketball.
As a side note, I don’t think it’s settled in evolutionary learning that breeding actually results in better performance that mutations alone. The problem is that the characteristics are not well encapsulated in most cases. Each bot may be good for entirely different reasons and mixing them could actually be worse.
So our basic algorithm is this:
- Create a population
- Score the population
- Kill off all but the best X%
- Mutate
- Breed
- Go back to step 2
And that’s pretty much it. Here’s the implementation below:
One thing I added that I had not discussed was curiosity. This is just adjusting the function used to score each individual to include a bonus for bots that explore their space. This is important if rewards are sparse. So for instance, if you only receive a reward after the game is complete, the likelihood that your bot will be able to beat the game immediately may be low. So if every bot is returning the same reward, there’s nothing distinguishing your bots, even though some may be much closer to completion than others.
Even though evolutionary models are relatively easy to implement and understand on the conceptual level, they are not very efficient, especially for environments that have a large state space or expensive evaluation functions. We’re essentially just choosing a model and tweaking it until it gets a good result, but how we’re tweaking it is completely random. A better methods could be to use derivatives to tweak the network in such a way that it will get a better result. Also, consider the number of trials we’re running. It’s not a problem on simple environments but it will be if the cost of running a trial is more expensive. And we’re throwing away a lot of data. A bot may be really strong in the beginning but have a flaw at one particular time. And if it doesn’t have an exceptional score, we just throw away everything we’ve learned. The next post will address just these issues.
That being said, evolutionary methods are still a useful tool to have and the principals can be incorporated into a lot of different methods as well.
To see evolutionary methods in action, you can see my entire Jupyter Notebook.
By Branko Blagojevic on February 5, 2018