A recent blog post caught my attention. The author wanted to see how long it would take for him to get an identical distribution of Skittles in a bag. He estimated a reasonable estimate of 400–500 bags would be required for him to open before he found a matching bag. After [spoiler alert] 468 bags, he finally found a matching bag.
I wanted to test this his results empirically while also being lazy. So I setup a simulation in python.
The get_bag function returns a bag of skittles with an input of a mean deviation for the number of skittles in the bag:
> get_bag(2)
'g:12;o:11;p:16;r:9;y:11'
The find_match function just keeps running trials until it gets a matching set, and then returns the number of trials run.
Here’s the output from my simulation of 1,000 trials:
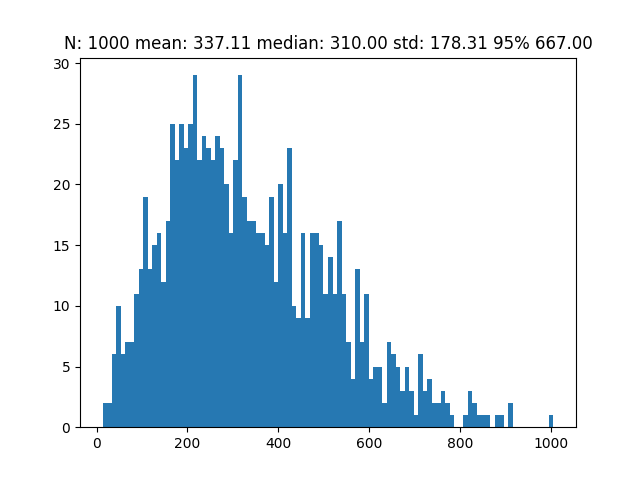
The median amount of bags required to find a matching bag was 310. 95% of the trials found a matching bag in 667 trials or less.
Assumptions
The author found the average number of skittles per bag was 59.27. He didn’t state the standard deviation of the bag size, but from the histogram I guessed it was +/- 2.
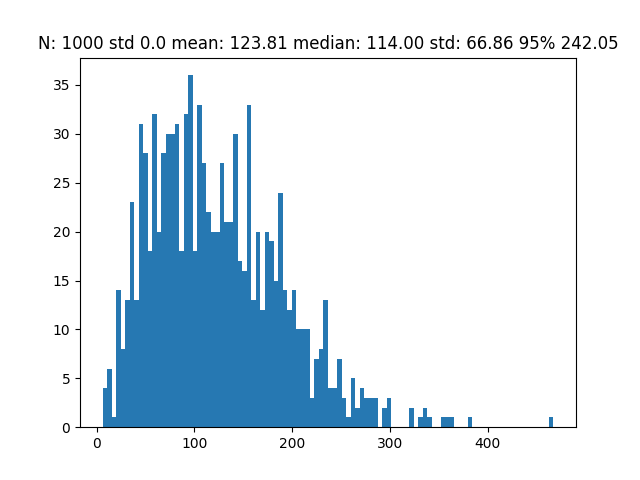
If every bag had exactly 59 skittles, the number of bags required to find a matching bag changes drastically.
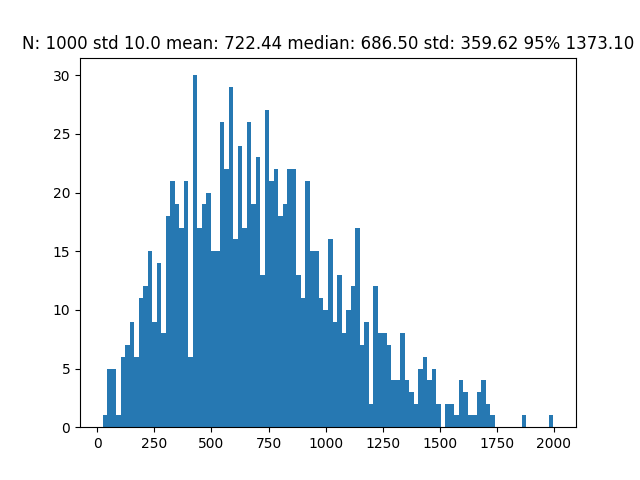
While with a standard deviation of 10, it would have probably taken around 700
I always find probability to be a bit intimidating, so I prefer simulations, especially when I’m trying to get a ballpark. We can get the same results without the diabetes.